How to make your code more readable — focus on the happy path and reduce cyclomatic complexity!

In your job as a software engineer, you might have stumbled upon many different types of code. You find the well-crafted, well-documented code that is a blast to work in given the simplicity and many unit tests to notify you when changing the code will result in an error.
You might also have stumbled upon some code where either the software engineer didn’t know better, didn’t care about the next software engineer to maintain it, or was in a rush due to deadlines that the quick and dirty solution was the only way.
You have this function in your codebase, that will create a customer based on a Customer Model you pass it.
This function, even though it works and has not caused any bugs, it is much harder to read. If you are at the same time in a position where you have to introduce some new logic in this function, then good luck! :)
This is just a simple example I created in a couple of minutes, but I’ve seen code with multiple lines of code where the cyclomatic complexity is so high, and changes of introducing a bug is very high.
Wait... What is cyclomatic complexity?
You have just created a function in your system and want to determine how ‘complex’ the function is. But how do you determine that? Is it several lines? is it a fancy way of using the reduce function?
Thomas J. McCabe introduced cyclomatic complexity as a metric to determine the level of complexity by looking at the linearly independent paths.
A linearly independent path in this scenario is whenever I introduce an if/else statement, the control flows now have the option to go 2 ways. That leads to 2 separate paths we need to take into consideration. Eventually, I will introduce a new if/else statement inside the body of the first if, leading to two new ways and introducing even more ‘complexity’.
How can we reduce the number of linearly independent paths?
Happy path coding
The happy path also called happy flow is a term used to describe a function where the best case journey is taken into consideration when coding. You write the code like no errors will ever happen, and expect the user to interact with your user interface the way you want to.
If the above code was only focusing on the happy path, the code would look like this.
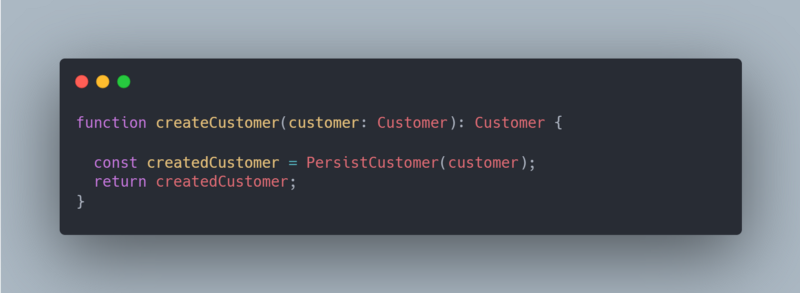
In this scenario, the customer is always passed as an argument, the name is set and the age is right. All this with only 2 lines of code.
Cool, so far so good.
Safeguarding with Inverted ifs
Now we want to check for the different scenarios as we do in the first example.
We do 3 checks (and no duplicated code!)
- Check if the customer is set
- Check if the name is not empty otherwise it is ‘Unknown’
- Check if the customer has valid age.
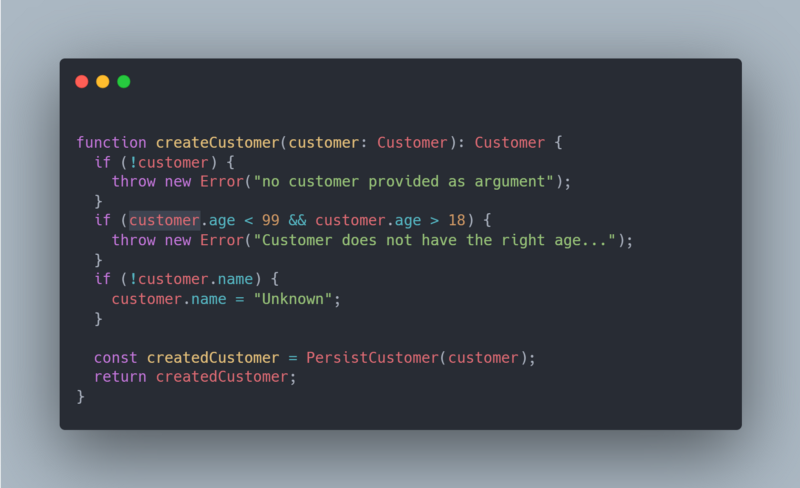
No duplicated code, no unnecessary nesting. The code is more readable, and you do not have to spend much time reading the code to understand the complexity, you can just focus on the happy path.